This page is to demostrate unshown experimental results, analysis, and audio samples for the FD-Bench project.
FD-Bench pipeline
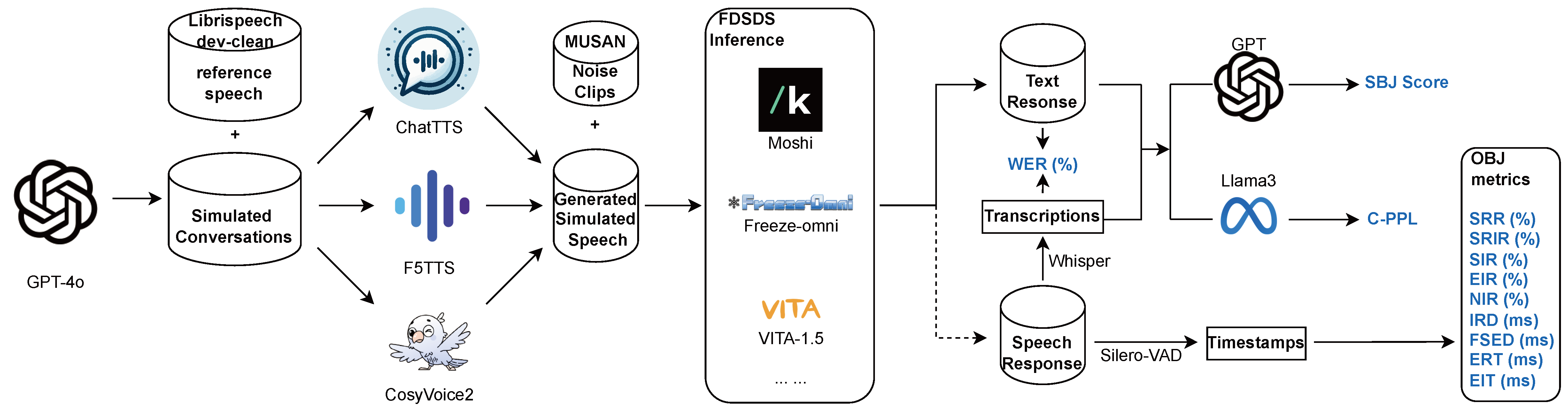 Figure 1: Pipeline for Benchmarking FDSDS: The framework integrates simulated conversations generated by GPT-4o and speech synthesis tools to produce input data. Noise samples and reference speech are used for diverse speakers and environments. The pipeline processes these inputs through duplex systems, incorporating Whisper for transcriptions and Silero-VAD for obtaining timestamps. Subjective scoring involves GPT inference, while Conditioned-PPL is from Llama3. Objective metrics are computed using timestamps.
Figure 1: Pipeline for Benchmarking FDSDS: The framework integrates simulated conversations generated by GPT-4o and speech synthesis tools to produce input data. Noise samples and reference speech are used for diverse speakers and environments. The pipeline processes these inputs through duplex systems, incorporating Whisper for transcriptions and Silero-VAD for obtaining timestamps. Subjective scoring involves GPT inference, while Conditioned-PPL is from Llama3. Objective metrics are computed using timestamps.
FD-Bench Metrics
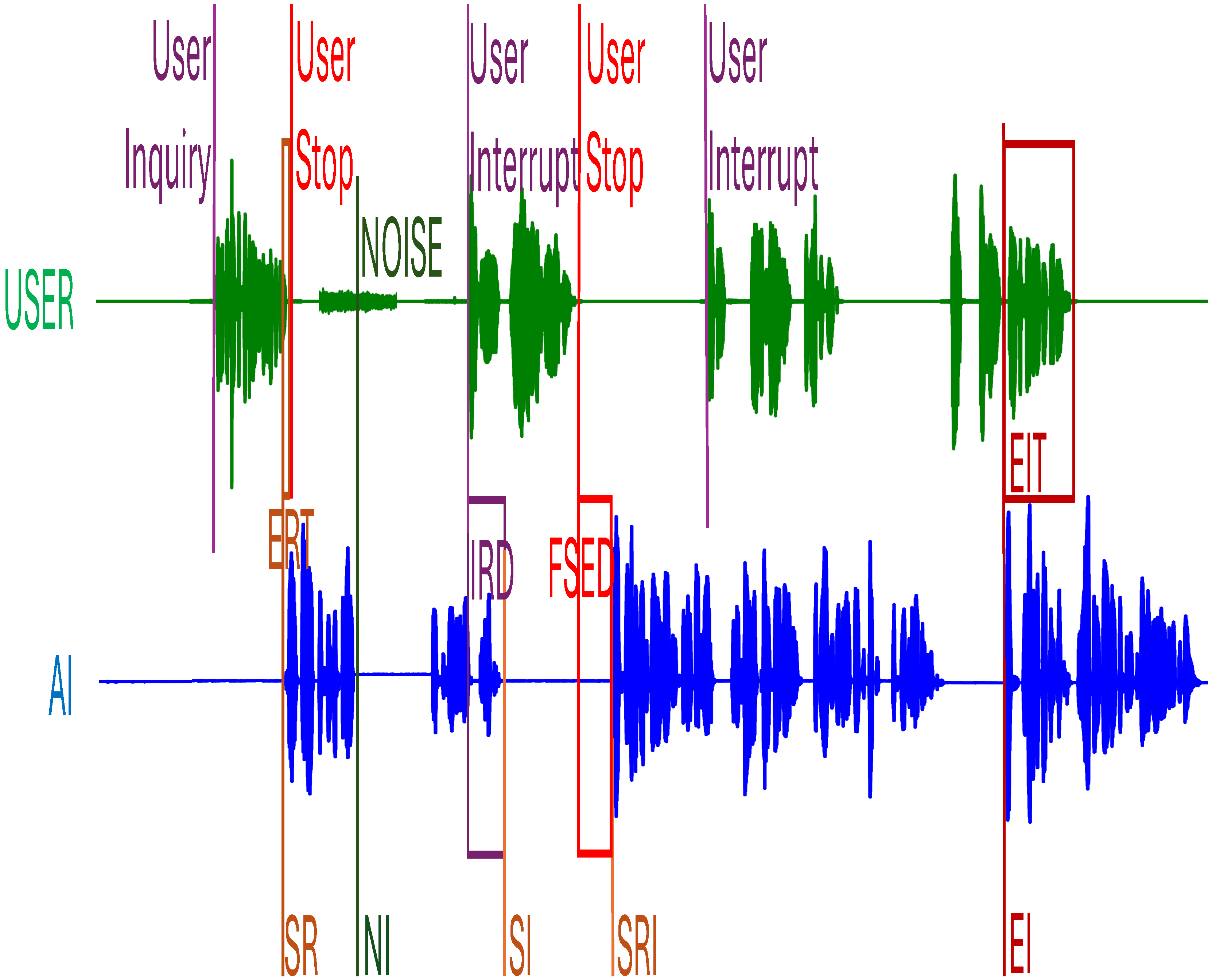
Figure 2: Visualization of real-time performance and interruption handling. In this example, AI successfully replies (SR) to the user inquiry (UI) with a slightly early reply time (ERT). Then, some noise from the user interrupts (NI) AI. AI resumes a reply, and the user interrupts, interruption response delays (IRD) the AI’s being successfully interrupted (SI). When the user stops the interruption, AI successfully replies to interruption (SRI) after the first speech emits delay (FSED). However, AI does not respond to the user’s next interruption and keeps talking. In the last round, AI early interrupts (EI) the user’s inquiry for early interrupt time (EIT) before the user finishes.
| Metric | Explanation |
|---|---|
| SRRate | Measures the odds of Success-Replies per User-non-interrupt inquiries. |
| SIRate | Measures the rates of Success-Interrupts per User-interrupt inquiries. |
| SRIRate | Measures the odds of Success-Replies-to-Interrupts per SI (successful interruptions). |
| EIRate | Measures the odds of Early-Interrupts per User inquiries. |
| NIRate | Measures the rates of Noise-Interrupts per Noise gaps between user inquiries. |
| IRD | Interrupt-response-delay: the delay between an interruption and the system’s response. |
| FSED | First-speech-emit-delay: the delay before the system emits its first speech. |
| ERT | Early-reply-time: indicates how soon the system replies, potentially before expected. |
| EIT | Early-interrupt-time: indicates how prematurely the system interrupts. |
| WER | Word-Error-Rate: evaluates the accuracy of generated speech against the output text, reflecting the overall fidelity of the spoken output. |
| Metric | Formula |
|---|---|
| C-PPL | \( \exp\left(-\frac{1}{N}\sum_{i=1}^{N}\log p\left(r_i \mid r_1,\dots,r_{i-1},\boldsymbol{c}\right) \right) \) |
| SRR | \( {\text{SRs}}/{\text{UIs}} \) |
| SRIR | \( {\text{SRs}_{\text{int}}}/{\text{UIs}_{\text{int}}} \) |
| SIR | \( {\text{SIs}_{\text{mdl}}}/{\text{UIs}_{\text{int}}} \) |
| EIR | \( {\text{EIs}_{\text{usr}}}/{\text{UIs}} \) |
| NIR | \( {\text{NIs}_{\text{mdl}}}/{\text{NIs}_{\text{usr}}} \) |
| IRD | \( \text{StopSpeak}_{\text{mdl}_{r-1}} - \text{StartSpeak}_{\text{usr}_{r}} \) |
| FSED | \( \text{StartSpeak}_{\text{mdl}_{r}} - \text{StopSpeak}_{\text{usr}_{r}} \) |
| ERT | \( \text{StopSpeak}_{\text{usr}_{t}} - \text{StartSpeak}_{\text{mdl}_{r}} \) |
| EIT | \( \text{StopSpeak}_{\text{usr}_{r}} - \text{StartSpeak}_{\text{mdl}_{t}} \) |